En tant que chef de projet ou chef de département, vous êtes probablement confronté à un volume impressionnant de données chaque jour. Vous avez des chiffres bruts tels que les heures enregistrées, les tâches assignées et les échéances qui se profilent à l'horizon. Mais extraire des informations pertinentes peut sembler impossible. Il s'agit d'un problème courant pour les professionnels qui ont besoin d'un regroupement personnalisé dans leurs rapports pour transformer le chaos informationnel en clarté stratégique.
Sans la capacité de classer et de découper efficacement vos données, vous risquez de passer à côté des tendances organisationnelles critiques. Un département est-il constamment surchargé alors qu'un autre reste sous-utilisé ? Les centres de coûts spécifiques à des clients épuisent-ils votre budget sans production proportionnelle ? Les données non structurées ne sont que du bruit ; seul un regroupement approprié permet de comprendre leur véritable nature et de prendre des décisions commerciales éclairées.
Dans cet article, nous explorerons l'importance théorique de la structuration des données et comment JFonctionnalité de Gira Group By vous permet de gérer des projets avec précision.
Pourquoi les données non structurées sont-elles l'ennemie d'une gestion efficace ?
Jira est une plateforme exceptionnelle qui permet de suivre les problèmes individuels et de détailler les tâches de manière précise. Cependant, ses rapports natifs fournissent souvent une vue « plate » qui échoue lorsque vous avez besoin d'une perspective stratégique de haut niveau. Vous pouvez voir une liste de tâches pour un utilisateur spécifique, mais vous ne pouvez pas facilement agréger ces données par « Service », « Centre de coûts » ou « Client ».
L'absence d'options de regroupement flexibles entraîne souvent plusieurs problèmes de gestion :
- Paralysie analytique : Les responsables passent des heures à exporter des données fixes vers des feuilles de calcul externes uniquement pour créer des tableaux croisés dynamiques pour les rapports de base.
- Goulots d'étranglement invisibles : Les problèmes de capacité restent cachés car les données sont éparpillées sur des centaines de lignes au lieu d'être résumées par compétence ou par rôle au sein de l'équipe.
- Le vide « non attribué » : Les éléments sans valeur dans les champs standard sont souvent regroupés dans des catégories génériques telles que « No Epic », ce qui rend les tâches incomplètes plus difficiles à repérer.
- Prise de décision réactive : Les décisions relatives aux ressources sont prises sur la base d'informations fragmentées, ce qui entraîne l'épuisement des équipes et le non-respect des étapes clés du projet.
Lorsque vous ne pouvez pas organiser les données en fonction de votre hiérarchie métier unique, vous les gérez de manière réactive plutôt que proactive.
Le pouvoir du contexte : transformer le bruit en informations
Le regroupement approprié des données est le processus qui consiste à regrouper les informations dans des catégories pertinentes afin de révéler des modèles cachés. Dans un contexte de gestion, cela signifie qu'il faut aller au-delà de « ce qui » se passe pour « pourquoi » et « où » cela se produit. Grâce à Jira Group By filed in reports, vous obtenez le contexte nécessaire pour que vos données deviennent un actif stratégique.
ActivityTimeline transforme l'expérience Jira en introduisant des fonctionnalités avancées de regroupement personnalisé. Cette fonctionnalité vous permet de restructurer la façon dont les données sont affichées dans l'ensemble de l'application, à l'aide de n'importe quel champ Jira standard ou personnalisé.
Cette fonctionnalité est disponible en trois modules clés, ce qui vous permet de disposer d'informations structurées à chaque étape de votre flux de gestion.
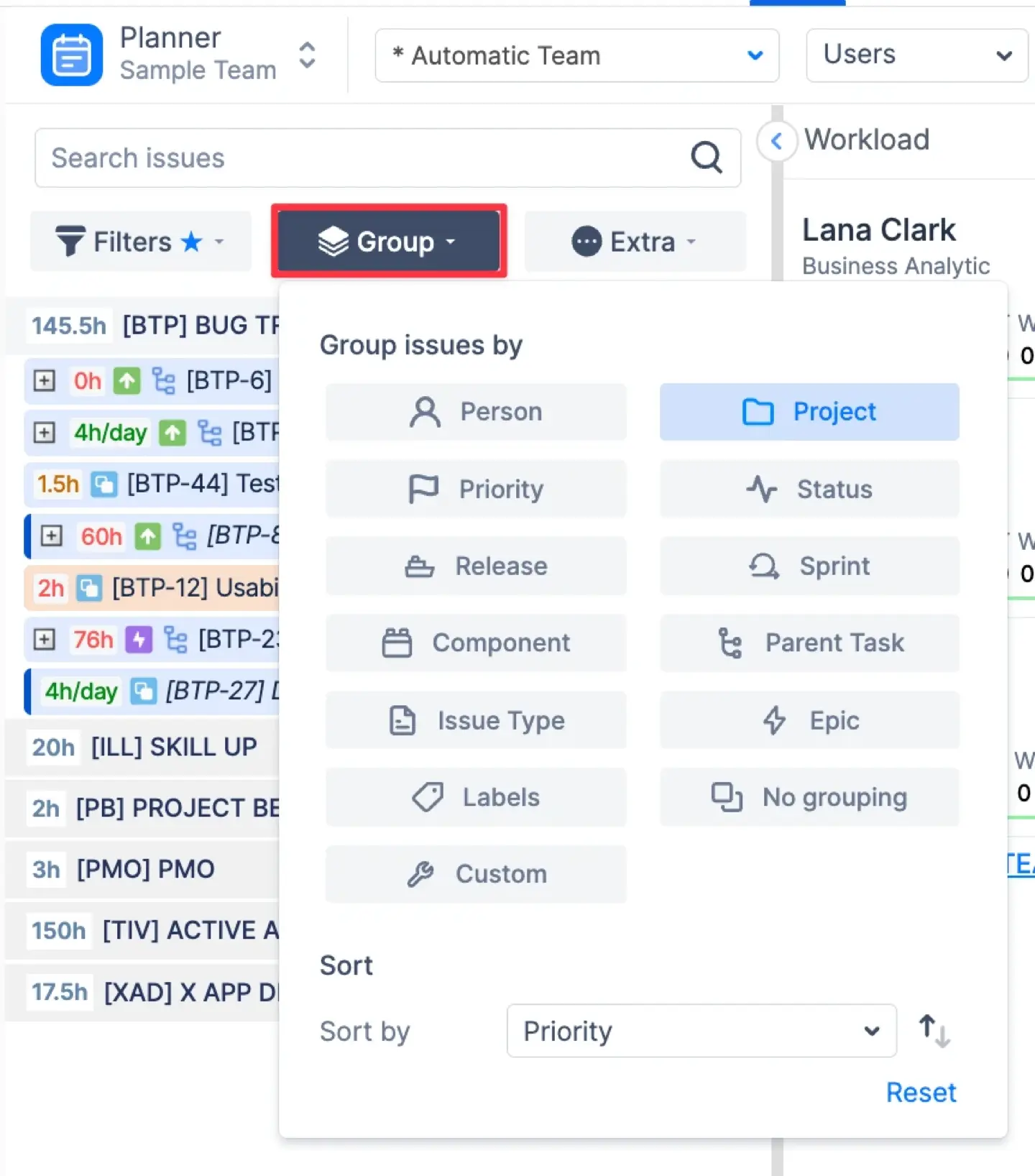
1. Rapports (analyses)
Il s'agit du principal moteur de votre prise de décision stratégique. Pour ajouter une option de regroupement à un rapport, sélectionnez des champs tels que « destinataire », « libellés » ou « composants » dans la liste déroulante de regroupement. Les gadgets du tableau de bord, tels que le gadget Pie Chart et le gadget Status & Progress Report, peuvent être utilisés pour visualiser les données des rapports groupés, en affichant la répartition des problèmes par statut, personne assignée ou priorité.
Vous pouvez regrouper les prévisions et rapports de projet pour analyser les capacités ou les progrès sous différents angles. Par exemple, vous pouvez consulter »Prévu ou réel groupées par « Epic » pour voir quelles initiatives majeures consomment le plus de ressources, ou regroupez-les par Sprint pour voir un résumé donnant un aperçu de l'état général du sprint.

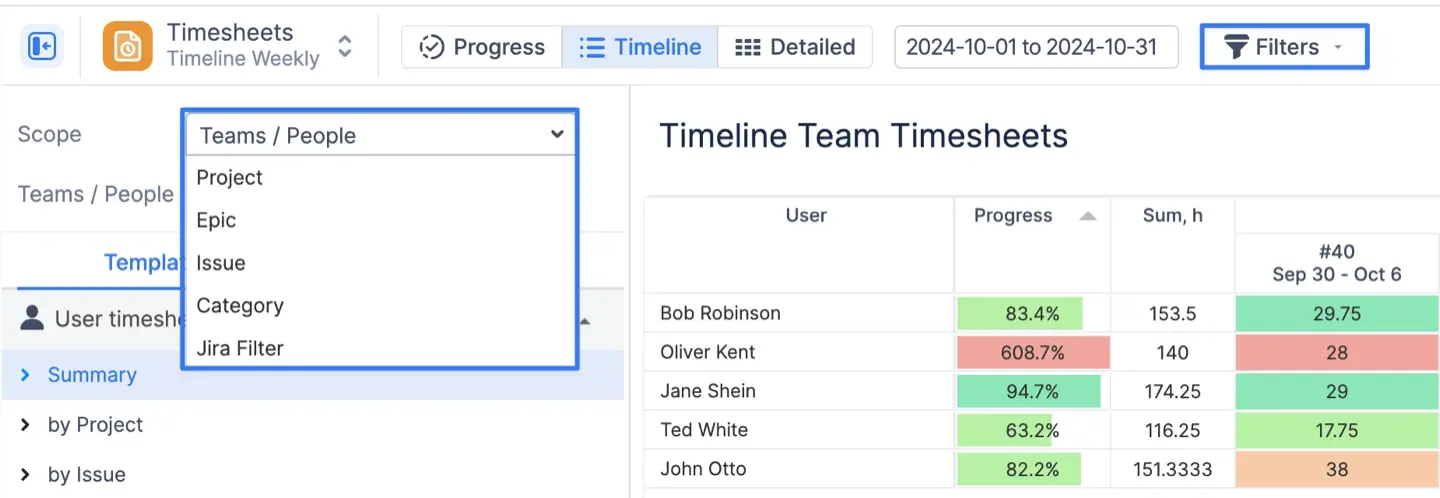
2. Feuilles de temps (piste)
Le suivi du temps nécessite des détails précis, mais vous avez également besoin de résumés globaux. Dans les vues Chronologie et Feuille de temps détaillée, vous pouvez regrouper les journaux de travail pour afficher les totaux par catégorie spécifique. Vous pouvez regrouper les données des feuilles de temps par destinataire, par étiquette ou par composant pour analyser les journaux de travail sous différents angles, par exemple par utilisateur assigné, par zone de projet ou par balises personnalisées. Un cas courant est le regroupement pour faire la distinction entre le travail facturable, les réunions internes et la formation.
3. Planificateur (panneau thématique)
Même la gestion de votre carnet de commandes bénéficie de cette flexibilité. Vous pouvez regrouper le backlog des tâches non planifiées par champs personnalisés afin de localiser les éléments de travail plus efficacement. Par exemple, vous pouvez « regrouper les problèmes par priorité ou par composant » pour vous assurer que votre équipe s'attaque en premier à la dette technique la plus critique. En outre, vous pouvez regrouper les éléments du backlog par personne assignée, par étiquette ou par composant afin de hiérarchiser et de gérer les tâches de manière plus efficace.
Réaliser un regroupement de données significatif
Jira Group By implique une approche structurée de l'affinement des données. ActivityTimeline a unifié ce flux de travail pour rendre la transition du bruit à l'analyse intuitive.
#1. Définition des paramètres de base
Un regroupement efficace commence par la définition de la portée de votre demande. Vous devez d'abord sélectionner le calendrier approprié et les équipes ou ressources spécifiques que vous souhaitez analyser. Sans ces limites, même les données groupées peuvent devenir écrasantes.
#2. Sélection de la hiérarchie de regroupement
Le choix du champ de regroupement détermine « l'histoire » racontée par le rapport. Un rapport groupé par « Epic » décrit l'avancement du projet ; un rapport groupé par « Client » décrit la rentabilité de l'entreprise. ActivityTimeline vous permet de choisir parmi les hiérarchies Jira standard ou tout autre champ personnalisé spécifique correspondant à la structure de votre entreprise interne.
#3. Raffinement dynamique
Le regroupement n'est pas une action statique ponctuelle. Après avoir généré un rapport, vous devrez peut-être affiner l'affichage en modifiant les pourcentages, en ajustant les filtres ou en masquant les tâches terminées pour réduire l'encombrement visuel. Ce processus itératif vous permet d'explorer des points de données spécifiques afin de découvrir la cause première des retards dans les projets ou des lacunes de capacité.
Rapports clés améliorés par le regroupement avancé
Pour optimiser la valeur de Jira Group By, concentrez-vous sur ces modèles de rapports à fort impact dans ActivityTimeline.
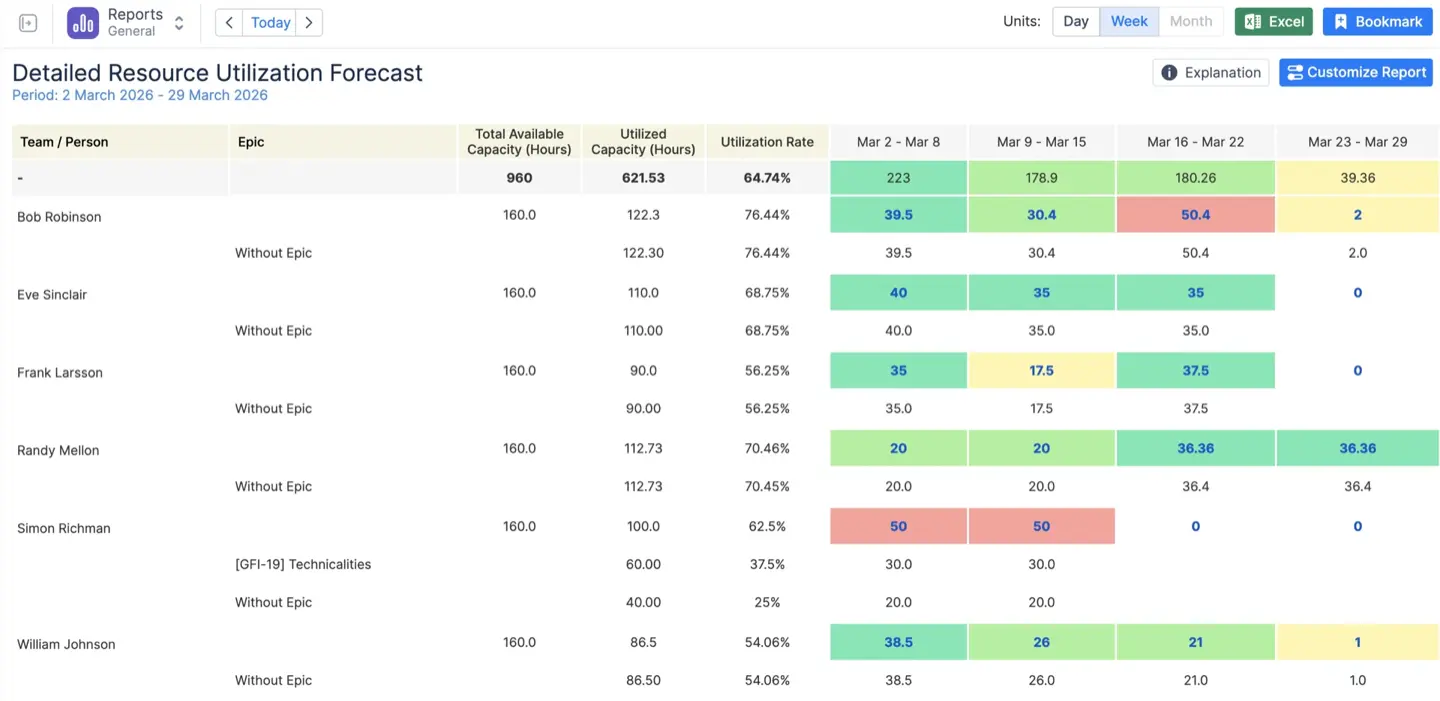
- Prévisions d'utilisation des ressources. Regroupez par problème, projet, épisode, personne assignée, étiquettes, composants ou champ personnalisé pour visualiser la répartition future de la charge de travail et obtenir des informations par utilisateurs, catégories ou segments de projet assignés.
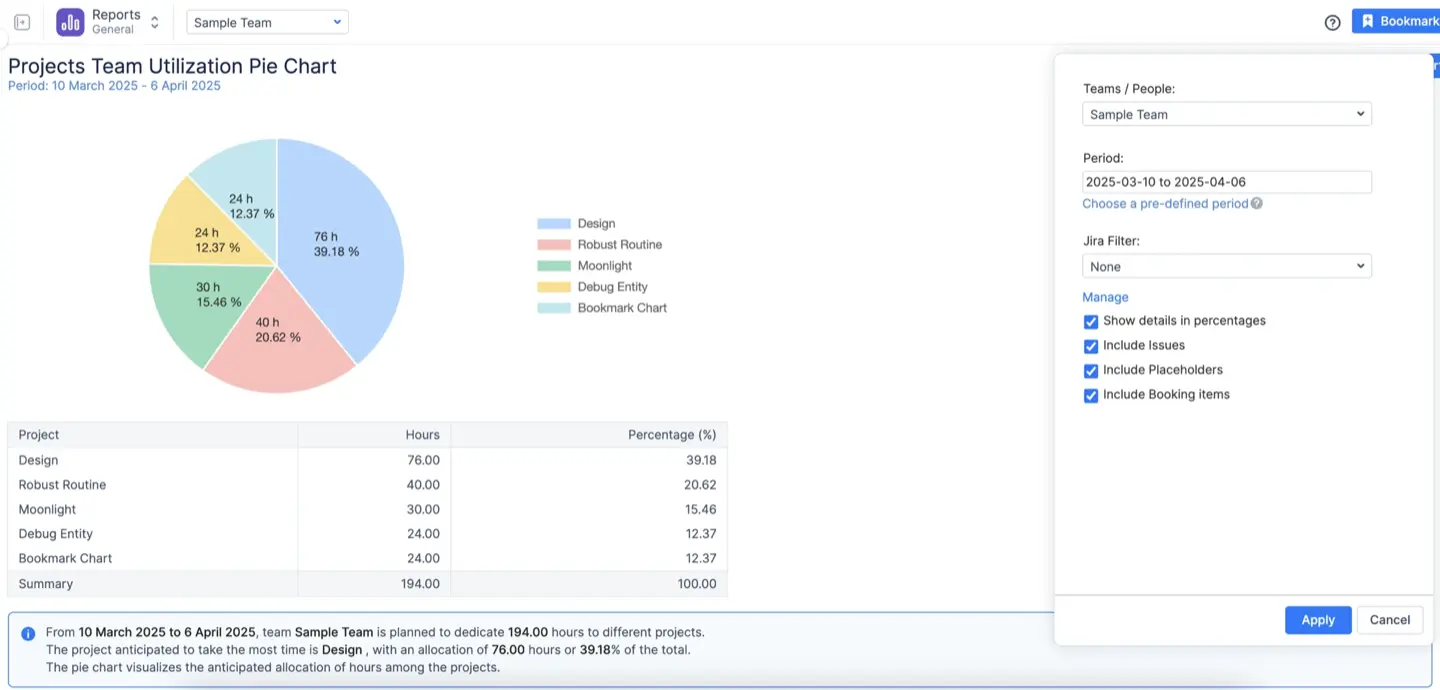
- Diagramme circulaire d'utilisation des équipes. Regroupez les données passées ou futures par champs personnalisés tels que « Statut facturable », Personne assignée, Étiquettes ou Composants pour obtenir un résumé visuel rapide et analyser le travail par membre de l'équipe, par tag ou par partie du projet.
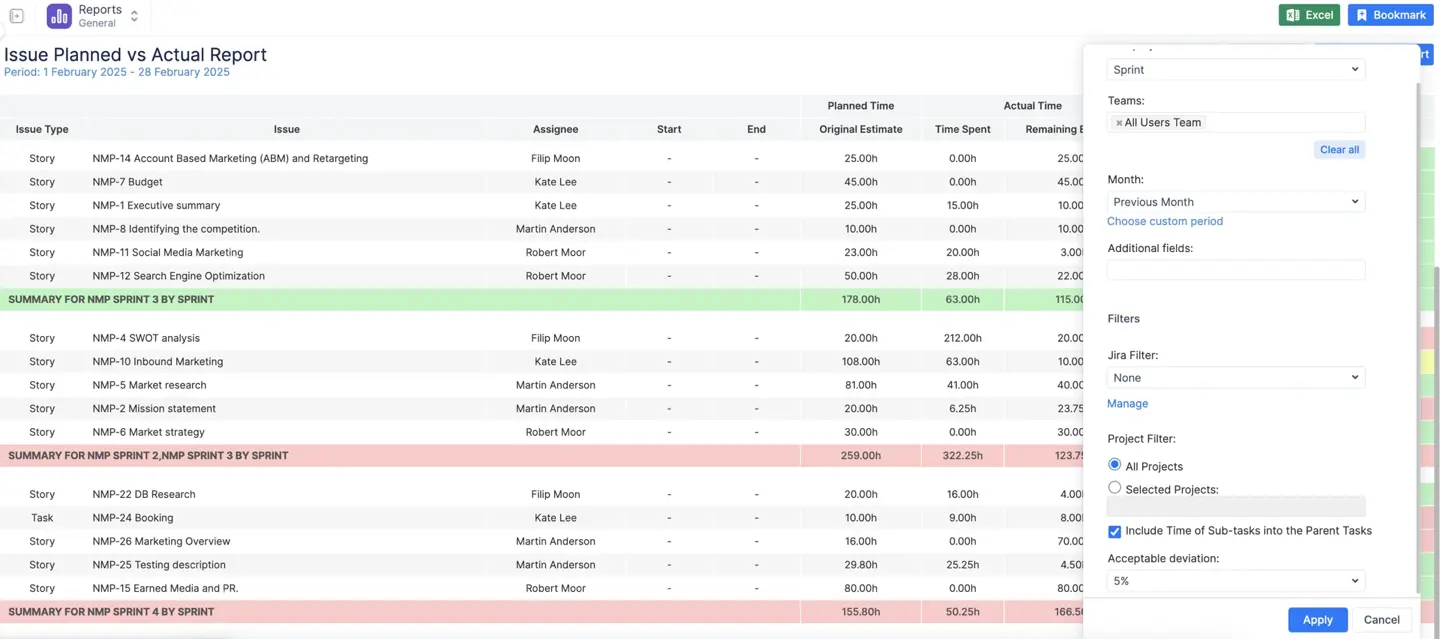
- Prévu ou réel. Regroupez par Epic, Composant, Personne assignée ou Libellé pour comparer les estimations à la réalité au niveau macroéconomique, ou pour voir les performances par utilisateur ou par catégorie.
- Rapport de journal de travail détaillé. Parfait pour la facturation, vous permettant de regrouper les articles par client, projet, cessionnaire, étiquettes ou composants pour une analyse et des rapports détaillés.
Conseil de pro : Une fois que vous avez configuré le rapport parfait avec votre groupe spécifique, utilisez Rapport sur les favoris fonctionnalité. Cela permet d'enregistrer la configuration pour un accès ultérieur en un clic, ce qui vous permet de gagner du temps sur les tâches de reporting récurrentes.
Conclusion
Les données non structurées constituent un handicap, mais les données contextualisées constituent un atout. En utilisant Jira Group By : regroupement personnalisé dans les rapports dans ActivityTimeline, vous allez au-delà de simples listes pour passer à une analyse hiérarchique sophistiquée. Que vous soyez suivi des heures facturables par client, suivi de la capacité par compétence ou analyse du projet Progrès réalisés par Epic, le regroupement personnalisé vous apporte la précision dont vous avez besoin pour gérer efficacement.
Arrêtez de vous battre avec des feuilles de calcul et commencez à prendre des décisions fondées sur des données dès aujourd'hui.
{{rich-cta-1}}